了解搜索引擎工作原理的SEOer都知道搜索引擎蜘蛛这个东西,spider这个东西我们做SEO的都很喜欢在日志中每天都看到他,恨不得分分钟的都让他出现在自己的网站上,为什么呢?因为只有他来了,我们的站点中的内容才有可能被索引,也就是被搜索引擎所收录,也只有被搜索引擎收录之后我们的站点信息才有可能被广大的网民找到并阅览。
我们先来普及以下什么是搜索引擎蜘蛛(spider),搜索引擎蜘蛛 (又被称为网页蜘蛛,网络机器人等),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。
我们也知道搜索引擎的工作原理简单的来说是:爬行抓取、预处理、排序这几个重要步骤,要想让站点有一个良好的排序,那么第一步的爬行和抓取是极其重要的。我们今天主要探讨的是诺大的一个互联网世界,海量的信息,亿万级别的网页,那么搜索引擎蜘蛛的出发地是在哪里呢?它这个小东西会从什么地方开始爬行互联网去抓取这些海量的信息呢?
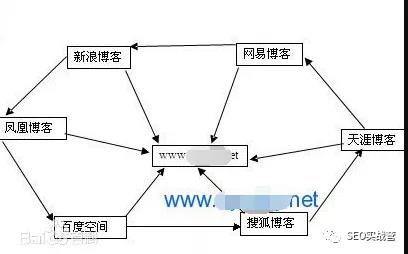
曾经从官方内部人士透露出来的信息是这样,他们说搜索引擎蜘蛛会从它认为最信任的网站开始爬行,然后顺着这些被信任的页面上出现的URL一直爬下去。这里有一个很重要的关键词“最信任的网站”,那么对于搜索引擎来说什么样的站点他最信任呢?
我个人的理解是这样的,那些被搜索引擎认可的,有一定权威性的,用户喜欢的站点,你比如说百度的新闻源站点,既然能成为百度的新闻源,那么肯定是被百度认可和信任的,这些站点搜索引擎蜘蛛就会极其频繁的爬行和抓取,至少5分钟一次。
还有就是对于百度自身来说,自己旗下的产品那肯定也是被非常信任的,比如知道、贴吧等,这些平台我估计蜘蛛就是常驻与此。
其实这些问题也不难理解,就像我们显示生活中人际交往是一样的,如果你想打听一件事情,你肯定是从自己身边最信任的人开始打听,然后慢慢延伸。搜索引擎蜘蛛也是如此。
当你明白了这个道理,也明白了蜘蛛的爬行起点,那么你是否也明白了如何让一个站点快速的被搜索引擎收录呢?
作者:周赛 更多分享来自: 转载请注明出处!
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!