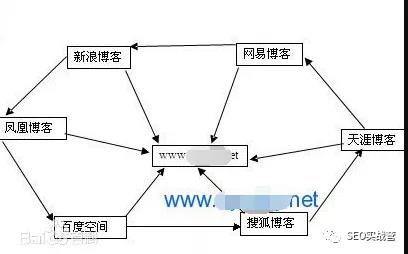
写这篇的动力源于上一篇中反复出现的robots,它让我想起了spider(蜘蛛)与crawler(爬虫)。此二者一样?不一样?
以前就看过一篇文章,说此二者不一样,或是严格说不一样。刚才又在网上搜了搜,大部分意见说此二者一样。这个大部分的意见,我就不在此熬述了,网上找吧,一大堆呢。我就这篇说说“此二者不一样”。对或不对,全当个参考,百家争鸣、百花齐放。
在 WebmasterWorld,曾有过个帖子,谈的就是spider与crawler。帖子开始就有一段叙述:
Search engines consist of five discrete software components:
Spider : a robotic browser like program that downloads webpages.
Crawler : a wandering spider that automatically follows links found on pages.
Indexer : a blender like program that dissects webpages that are downloaded by spiders.
The Database : a warehouse of the pages downloaded and processed.
Search Engine Results Engine : digs search results out of the database.
一句话总结一下它的意思,就是:spider与crawler不一样。
帖子里还有个观点,就是说robots有5种,其名称、作用依次是:spider,下载网页;crawler,顺着内链,访问该链接的另一 端;indexer,收录下载了的网页;datebase,下载了的、处理了的网页的仓库;result engine, 从数据库中找出搜索结果。5种?这个观点,我不知道是否正确,不过至少对我来说,够新颖的。
还有人发言道:
Let's talk about how robots interpret your page for a bit. If I follow Brett's historical topic, you have three different types of robots, a spider, crawler and indexer.
First the Spider comes around and requests the URI. It reads server header information and other on page information. Then the Crawler follows all the links within that domain (those that are found and allowed). Then the Indexer reads the html while making heads and tails of it.
其发言者认为robots有3种:spider、crawler、indexer。一开始是spider根据URI,访问进来,接着,读取服务器的header和网页的head标签。然后,crawler顺着spider发现的网页的内链,去访问该内链的另一端。最后,indexer来读取HTML代码。
大家是怎么看待这个问题呢?希望我这篇能起到抛砖引玉的作用。
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!