在数字化转型深度推进的当下,知识库建设已成为技术密集型企业提升核心竞争力的关键支撑。这类企业的研发创新高度依赖海量学术文献、技术报告、行业标准等专业文档,而这些文档多以非结构化PDF、扫描件形式存在,传统人工整理与简单OCR工具已难以满足大规模、高质量的知识转化需求,成为企业智能知识库构建的核心瓶颈。
科创板上市公司合合信息推出的TextIn文档解析解决方案,可高效破解非结构化文档解析难题,将海量学术论文高效转化为机器可读的结构化数据,成为企业构建可信AI知识库的“数据基座”。
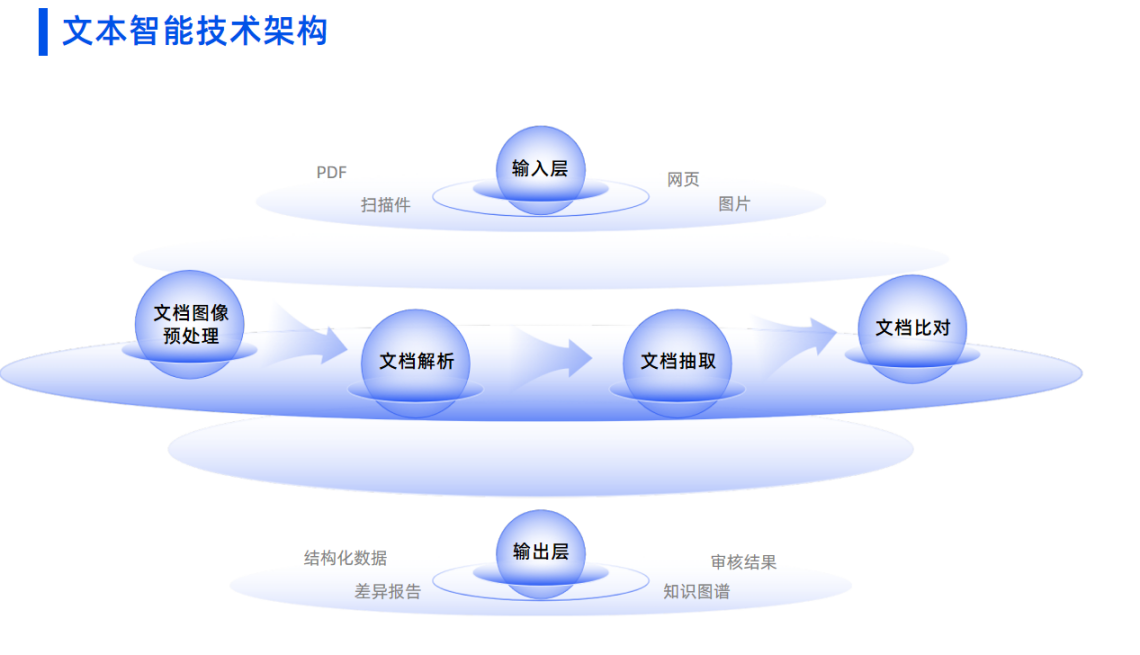
学术论文作为企业技术预研、产品迭代与专利布局的核心信息源,版式规范复杂、元素种类繁多,双栏排版、密集公式、复杂表格、专业图表等场景,对解析工具的精准度和兼容性提出极高要求。传统解析工具常出现正文与图注错位、公式识别乱码、表格结构丢失、图表无法数据化等问题,导致核心知识流失,直接影响后续检索与大模型问答的准确性。

针对上述痛点,TextIn文档解析提供了有效解决方案。在多栏布局解析方面,其基于版面分析技术,智能识别栏区域、段落区块及浮动元素,输出内容严格遵循原始阅读顺序,清晰标注标题层级、保留图文关系;在专业公式识别上,支持印刷体与手写体公式精准识别,可将各类复杂公式转换为LaTeX标准格式;针对复杂表格,能还原表头嵌套层级与合并单元格,自动合并跨页长表,完整保留数据关联;在图表处理上,可提取多种图表的坐标轴、图例及数据点,将视觉图表转化为结构化数据;同时,通过图像预处理模块解决文档倾斜、水印等质量问题,支持50多种语言及多格式文档统一处理。
实践中,TextIn已获得头部技术密集型企业认可。某头部医药企业引入该解决方案后,成功破解临床试验报告、生物医学文献的解析难题,支撑研发、供应链与质量等五大知识库构建;某头部半导体企业则借助其精准的密集文本、公式及表格解析能力,为模拟电路设计知识库提供了可靠的数据输入。
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!