


这篇文章主要介绍了postgresql 索引之 hash的使用详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧。
os: ubuntu 16.04
postgresql: 9.6.8
ip 规划
192.168.56.102 node2 postgresql
help create index
postgres=# \h create index
Command: CREATE INDEX
Description: define a new index
Syntax:
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON table_name [ USING method ]
( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ WITH ( storage_parameter = value [, ... ] ) ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ]
[ USING method ]
method
要使用的索引方法的名称。可以选择 btree、hash、 gist、spgist、 gin以及brin。 默认方法是btree。
hash
hash 只能处理简单的等值比较,
postgres=# drop table tmp_t0;
DROP TABLE
postgres=# create table tmp_t0(c0 varchar(100),c1 varchar(100));
CREATE TABLE
postgres=# insert into tmp_t0(c0,c1) select md5(id::varchar),md5((id+id)::varchar) from generate_series(1,100000) as id;
INSERT 0 100000
postgres=# create index idx_tmp_t0_1 on tmp_t0 using hash(c0);
CREATE INDEX
postgres=# \d+ tmp_t0
Table "public.tmp_t0"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+------------------------+-----------+----------+---------+----------+--------------+-------------
c0 | character varying(100) | | | | extended | |
c1 | character varying(100) | | | | extended | |
Indexes:
"idx_tmp_t0_1" hash (c0)
postgres=# explain select * from tmp_t0 where c0 = 'd3d9446802a44259755d38e6d163e820';
QUERY PLAN
----------------------------------------------------------------------------
Index Scan using idx_tmp_t0_1 on tmp_t0 (cost=0.00..8.02 rows=1 width=66)
Index Cond: ((c0)::text = 'd3d9446802a44259755d38e6d163e820'::text)
(2 rows)
注意事项,官网特别强调:
Hash索引操作目前不被WAL记录,因此存在未写入修改,在数据库崩溃后需要用REINDEX命令重建Hash索引。
同样,在完成初始的基础备份后,对于Hash索引的改变也不会通过流式或基于文件的复制所复制,所以它们会对其后使用它们的查询给出错误的答案。
正因为这些原因,Hash索引已不再被建议使用。
补充:Postgresql hash索引介绍
hash索引的结构
当数据插入索引时,我们会为这个索引键通过哈希函数计算一个值。 PostgreSQL中的哈希函数始终返回“整数”类型,范围为2^32≈40亿。bucket桶的数量最初为2个,然后动态增加以适应数据大小。可以使用位算法从哈希码计算出桶编号。这个bucket将存放TID。
由于可以将与不同索引键匹配的TID放入同一bucket桶中。而且除了TID之外,还可以将键的源值存储在bucket桶中,但这会增加索引大小。为了节省空间,bucket桶只存储索引键的哈希码,而不存储索引键。
当我们通过索引查询时,我们计算索引键的哈希函数并获取bucket桶的编号。现在,仍然需要遍历存储桶的内容,并仅返回所需的哈希码匹配的TID。由于存储的“hash code - TID”对是有序的,因此可以高效地完成此操作。
但是,两个不同的索引键可能会发生以下情况,两个索引键都进入一个bucket桶,而且具有相同的四字节的哈希码。因此,索引访问方法要求索引引擎重新检查表行中的情况来验证每个TID。
映射数据结构到page
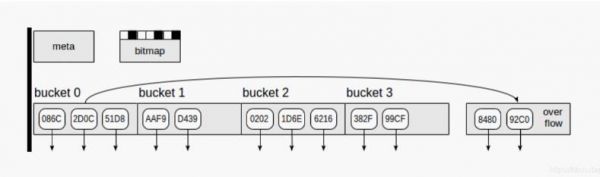
Meta page - 0号page,包含索引内部相关信息
Bucket pages - 索引的主要page,存储 “hash code - TID” 对
Overflow pages - 与bucket page的结构相同,在不足一个page时,作为bucket桶使用
Bitmap pages - 跟踪当前干净的overflow page,并可将其重新用于其他bucket桶
注意,哈希索引不能减小大小。虽然我们删除了一些索引行,但是分配的页面将不会返回到操作系统,只会在VACUUMING之后重新用于新数据。减小索引大小的唯一选项是使用REINDEX或VACUUM FULL命令从头开始重建索引
接下来看下hash索引如何创建
demo=# create index on flights using hash(flight_no);
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
注意:10版本之前hash索引不记录到wal中,所以hash索引不能做recovery,当然也就不能复制了,但是从10版本以后hash所用得到了增强,可以记录到wal中,创建的时候也不会再有警告。
查看hash访问方法相关的操作函数
demo=# select opf.opfname as opfamily_name,
amproc.amproc::regproc AS opfamily_procedure
from pg_am am,
pg_opfamily opf,
pg_amproc amproc
where opf.opfmethod = am.oid
and amproc.amprocfamily = opf.oid
and am.amname = 'hash'
order by opfamily_name,
opfamily_procedure;
opfamily_name | opfamily_procedure
--------------------+-------------------------
abstime_ops | hashint4extended
abstime_ops | hashint4
aclitem_ops | hash_aclitem
aclitem_ops | hash_aclitem_extended
array_ops | hash_array
array_ops | hash_array_extended
bool_ops | hashcharextended
bool_ops | hashchar
bpchar_ops | hashbpcharextended
bpchar_ops | hashbpchar
bpchar_pattern_ops | hashbpcharextended
bpchar_pattern_ops | hashbpchar
bytea_ops | hashvarlena
bytea_ops | hashvarlenaextended
char_ops | hashcharextended
char_ops | hashchar
cid_ops | hashint4extended
cid_ops | hashint4
date_ops | hashint4extended
date_ops | hashint4
enum_ops | hashenumextended
enum_ops | hashenum
float_ops | hashfloat4extended
float_ops | hashfloat8extended
float_ops | hashfloat4
float_ops | hashfloat8
...
可以用这些函数计算相关类型的哈希码
hank=# select hashtext('zhang');
hashtext
-------------
-1172392837
(1 row)
hank=# select hashint4(10);
hashint4
-------------
-1547814713
(1 row)
hash索引相关的属性
hank=# select a.amname, p.name, pg_indexam_has_property(a.oid,p.name)
hank-# from pg_am a,
hank-# unnest(array['can_order','can_unique','can_multi_col','can_exclude']) p(name)
hank-# where a.amname = 'hash'
hank-# order by a.amname;
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
hash | can_order | f
hash | can_unique | f
hash | can_multi_col | f
hash | can_exclude | t
(4 rows)
hank=# select p.name, pg_index_has_property('hank.idx_test_name'::regclass,p.name)
hank-# from unnest(array[
hank(# 'clusterable','index_scan','bitmap_scan','backward_scan'
hank(# ]) p(name);
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t
bitmap_scan | t
backward_scan | t
(4 rows)
hank=# select p.name,
hank-# pg_index_column_has_property('hank.idx_test_name'::regclass,1,p.name)
hank-# from unnest(array[
hank(# 'asc','desc','nulls_first','nulls_last','orderable','distance_orderable',
hank(# 'returnable','search_array','search_nulls'
hank(# ]) p(name);
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | f
search_array | f
search_nulls | f
(9 rows)
由于hash函数没有特定的排序规则,所以一般的hash索引只支持等值查询,可以通过下面数据字典看到,所有操作都是“=”,而且hash索引也不会处理null值,所以不会标记null值,还有就是hash索引不存储索引键,只存储hash码,所以不会 index-only扫描,也不支持多列创建hash索引
hank=# select opf.opfname AS opfamily_name,
hank-# amop.amopopr::regoperator AS opfamily_operator
hank-# from pg_am am,
hank-# pg_opfamily opf,
hank-# pg_amop amop
hank-# where opf.opfmethod = am.oid
hank-# and amop.amopfamily = opf.oid
hank-# and am.amname = 'hash'
hank-# order by opfamily_name,
hank-# opfamily_operator;
opfamily_name | opfamily_operator
--------------------+------------------------------------------------------------
abstime_ops | =(abstime,abstime)
aclitem_ops | =(aclitem,aclitem)
array_ops | =(anyarray,anyarray)
bool_ops | =(boolean,boolean)
bpchar_ops | =(character,character)
bpchar_pattern_ops | =(character,character)
bytea_ops | =(bytea,bytea)
char_ops | =("char","char")
cid_ops | =(cid,cid)
date_ops | =(date,date)
enum_ops | =(anyenum,anyenum)
float_ops | =(real,real)
float_ops | =(double precision,double precision)
float_ops | =(real,double precision)
float_ops | =(double precision,real)
hash_hstore_ops | =(hstore,hstore)
integer_ops | =(integer,bigint)
integer_ops | =(smallint,smallint)
integer_ops | =(integer,integer)
integer_ops | =(bigint,bigint)
integer_ops | =(bigint,integer)
integer_ops | =(smallint,integer)
integer_ops | =(integer,smallint)
integer_ops | =(smallint,bigint)
integer_ops | =(bigint,smallint)
interval_ops | =(interval,interval)
jsonb_ops | =(jsonb,jsonb)
macaddr8_ops | =(macaddr8,macaddr8)
macaddr_ops | =(macaddr,macaddr)
name_ops | =(name,name)
network_ops | =(inet,inet)
numeric_ops | =(numeric,numeric)
oid_ops | =(oid,oid)
oidvector_ops | =(oidvector,oidvector)
pg_lsn_ops | =(pg_lsn,pg_lsn)
range_ops | =(anyrange,anyrange)
reltime_ops | =(reltime,reltime)
text_ops | =(text,text)
text_pattern_ops | =(text,text)
time_ops | =(time without time zone,time without time zone)
timestamp_ops | =(timestamp without time zone,timestamp without time zone)
timestamptz_ops | =(timestamp with time zone,timestamp with time zone)
timetz_ops | =(time with time zone,time with time zone)
uuid_ops | =(uuid,uuid)
xid_ops | =(xid,xid)
从10版本开始,可以通过pageinspect插件查看hash索引的内部情况
安装插件
1create extension pageinspect;
查看0号page
hank=# select hash_page_type(get_raw_page('hank.idx_test_name',0));
hash_page_type
----------------
metapage
(1 row)
查看索引中的行数和已用的最大存储桶数
hank=# select ntuples, maxbucket
hank-# from hash_metapage_info(get_raw_page('hank.idx_test_name',0));
ntuples | maxbucket
---------+-----------
1000 | 3
(1 row)
可以看到1号page是bucket,查看此bucket page的活动元组和死元组的数量,
也就是膨胀度,以便维护索引
hank=# select hash_page_type(get_raw_page('hank.idx_test_name',1));
hash_page_type
----------------
bucket
(1 row)
hank=# select live_items, dead_items
hank-# from hash_page_stats(get_raw_page('hank.idx_test_name',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
文章来源:脚本之家
来源地址:https://www.jb51.net/article/205229.htm
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!

