这篇文章主要介绍了sqlserver查询去掉重复数据的实现操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
说明:
只要数据表“列名”数据相同,则说明是两条重复的数据(ID为数据表的主键自动增长)。
推荐使用方法一
-- 方法一
select * from 表名 A where not exists(select 1 from 表名 where 列名=A.列名 and ID<A.ID)
-- 方法二
select A.* from 表名 A inner join (select min(ID) ID,列名 from 表名 group by 列名) B on A.列名=B.列名 and A.ID=B.ID
-- 方法三
select * from 表名 A where ID=(select min(ID) from 表名 where 列名=A.列名)
补充:SQL SERVER 查询去重 PARTITION BY
rownumber() over(partition by col1 order by col2)
去重的方法,很不错,在此记录下:
row_number() OVER ( PARTITION BY COL1 ORDER BY COL2)
表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的).
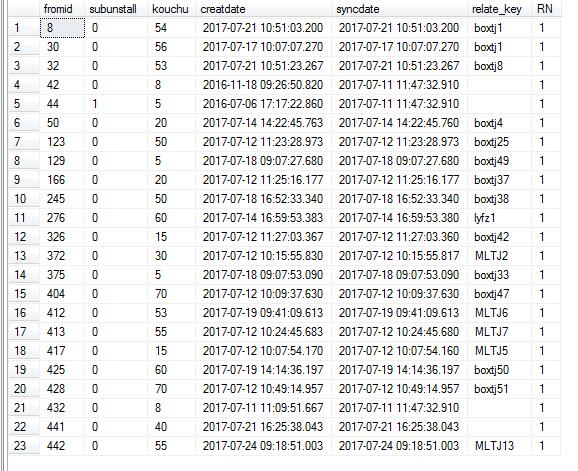
直接查询,中间很多相同的,但我只想取createdate时间最大的一条
select fromid,subunstall,kouchu,creatdate,syncdate,relate_key from BoxCount_Froms_Open

使用
PARTITION BY fromid ORDER BY creatdate DESC
根据中的 fromid分组,根据creatdate组内排序
WHERE RN= 1;取第一条数据
SELECT * FROM (SELECT fromid,subunstall,kouchu,creatdate,syncdate,relate_key,ROW_NUMBER() OVER( PARTITION BY fromid ORDER BY creatdate DESC)RN FROM BoxCount_Froms_Open ) T WHERE RN= 1;
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
来源:脚本之家
链接:https://www.jb51.net/article/204063.htm
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!