四月初,开源AI智能体OpenClaw(“龙虾”)发布v2026.4.5版本,将视频、音乐、图像三大核心生成能力内置为系统原生工具,同时首次引入“Dreaming”记忆系统,通过模拟人类睡眠记忆机制,分三阶段(Light/Deep/REM)优化智能体记忆能力,从而实现7x24小时无人值守运行。然而,功能的大幅升级也对存储性能提出了更严苛的要求:百GB级大模型需秒级加载,海量小文件须无卡顿频繁读写,持续高负载下性能不可衰减。一旦SSD成为瓶颈,智能体将面临响应延迟甚至任务失败。
为此,忆联推出面向OEM市场的消费级PCIe 5.0 SSD——AM6D1。该产品采用DRAMLess架构,顺序读写高达11.4/10.9GB/s(2TB),随机读写高达1600/1150K IOPS(2TB)。实测显示,DeepSeek R1 14B模型加载仅需5.888秒;SLC写入达10685MB/s,4K随机重复读取达758 MB/s;即便SLC缓存耗尽,TLC直写仍能维持2198MB/s,性能显著优于同类产品。
AM6D1以高性价比与高可靠性,为OpenClaw等AI智能体铸就了强劲的存储“心脏”。当“龙虾”从“对话工具”升级为“具备长期记忆的创作引擎”,一台搭载AM6D1的PC,便是未来最高效的“打工人”。

● 性能跃升,打破AI加载瓶颈
测试环境
测试平台
Legion Y9000P IAX10
处理器
Intel(R) Core(TM) Ultra 9 275HX
显卡
NVIDIA GeForce RTX 5060 Laptop GPU
内存
32G
硬盘
AM6D1 1TB(2242)
电源
300W
操作系统
Windows 11 25H2
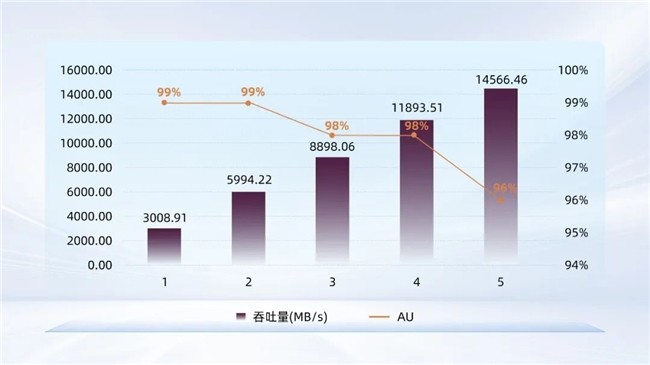
在CDM基准测试中,AM6D1实现了顺序读写10.7/10.6GB/s(1TB)、随机读写1500/1150K IOPS(1TB)的标称性能,并在关键指标上明显优于友商。其中,Q8T1顺序写性能达10684MB/s,友商A与友商B同类PCIe 5.0产品分别为9507MB/s和10198MB/s;Q32T16随机读性能达1640K IOPS,显著超越友商A的1430K IOPS及友商B的1470K IOPS。

在DeepSeek实际场景中, R1 14B本地大模型加载仅需5.888秒。这意味着,当 OpenClaw启动并调用本地AI模型时,几乎无需等待,智能体可即刻进入工作状态。
● 深度适配,日常交互丝滑流畅
针对AI智能体典型的混合负载场景(突发大块写入+海量小数据反复读写),AM6D1通过动态SLC缓存与智能预读实现深度适配。静态/动态SLC策略根据实时负载优化突发写入性能,配合预读硬加速技术,提前加载可能访问的数据,显著降低延迟。
实测显示,其SLC写入达10685MB/s,优于友商A的9513MB/s和友商B的10198MB/s;4K随机重复读取达758MB/s,同样大幅领先友商B。无论是大文件突发写入,还是代码编辑、日志分析等小文件密集型任务,AM6D1均可提供丝滑流畅的体验。

● 稳定可靠,高负载下稳态运行
OpenClaw等需长时间后台运行的Agent,对高负载下的性能稳定性要求极高。AM6D1通过TLC单元优化与固件算法升级,展现出卓越的稳态表现。
测试数据显示,即便SLC缓存用尽,其TLC直写性能仍可达2198MB/s,远超友商A的1795MB/s和友商B的1782MB/s。这意味着,在持续高压力写入场景下,AM6D1依然能够保持稳定高性能,为OpenClaw等后台Agent提供可靠保障。

从“会聊天”到“会干活”,OpenClaw正进化为生产级AI伙伴。忆联AM6D1——以DRAMLess架构打破高性能与高成本的壁垒,以极致稳定的PCIe 5.0性能,为智能体铸就起强劲的存储“心脏”。当“龙虾”从“对话工具”升级为“具备长期记忆的创作引擎”,一台搭载AM6D1的PC,就是未来最高效的“打工人”。
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!