最近,OpenAI的Sora又在科技圈投入一枚深水炸弹。全球对于大模型的关注,又一次达到高峰。
聚焦到国内,百度、科大讯飞、商汤、华为等大型企业,以及海量的创业小公司都在布局大模型。以往每一次风口吹来的时候,资本总会蜂拥而上。但是,此次大模型热潮涌来之时,资本的反应很奇怪——讨论度很高但参与度却不高,赛道的投融资并没有想象中火爆。
研究机构CB Insights发布的《2023年人工智能(AI)行业现状报告》(简称“报告”)显示,2023年中国AI领域投融资数量约为232笔,同比下降38%;融资总额约为20亿美元,同比下降70%。其中,AI大模型的融资活动也没有呈现上升态势。
今年以来,不少投资人对大模型变得更加审慎,“谈得多、投得少”成为常态。某投资人告诉《一点财经》,现在国内资本圈对于大模型持观望态度的机构变得更多了,因为大家担心大模型在去年经历了一轮爆火之后,变得估值虚高形成了泡沫。
连街头大妈都知道,AI大模型是当下最热门的科技话题,为何在国内大模型似乎受到资本“冷落”?国产大模型,为何没有引爆一场“烧钱游戏”?

国产大模型,“冷热”分明
上一个像AI大模型一样热闹的风口,还是十年前的移动互联网。十年之后,移动互联网声势渐弱,换AI大模型来接棒。
ChatGPT的横空出世,拉开AI大模型的全球竞速,热钱迅速涌来,也催生出巨大的市场空间。中研普华产业研究院数据显示,2024年全球大模型市场规模将达到280亿美元,并在2028年形成千亿美金的巨大蛋糕。
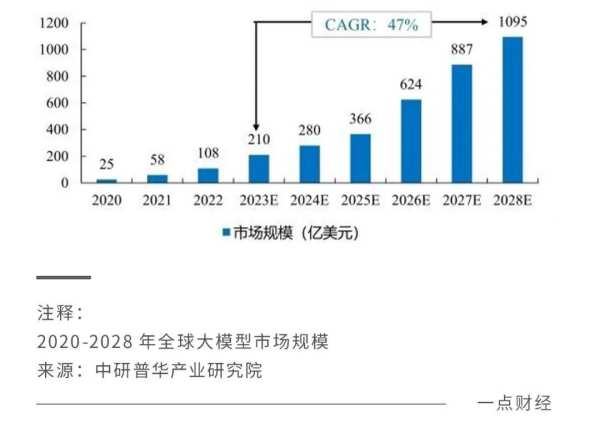
中国市场的大模型也呈井喷态势,在去年的前11个月,国内发布了238个大模型,平均每天都有一个大模型问世,从而掀起一场“百模大战”。
在这场“百模大战”里,互联网大厂是绝对的主力军。市面上的主流大模型厂商中,互联网玩家几乎占据半壁江山,比如百度的文心大模型、科大讯飞的星火大模型、阿里的通义大模型、腾讯的混元大模型等,华为、京东等科技公司也发布了自家的大模型。
不过,国产大模型的投资力度,并没有跟发布数量一样,呈大幅上升的趋势。IT桔子数据显示,2021年~2023年,中国AI领域一级市场的股权融资的数量和金融都呈下降趋势,大模型的投资也没有呈大幅上升的迹象。
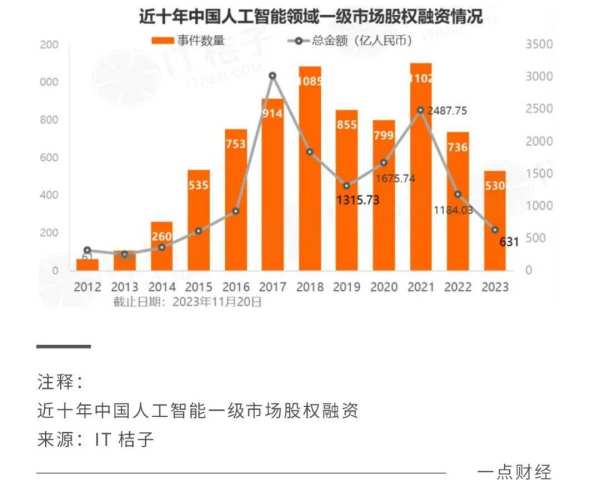
一方面是投资并没有想象中的火热,另一方面是投资变得高度集中,都流向了头部的一些大模型项目。
去年下半年开始,投资方基本就筛选出了大模型创业公司里的种子选手。据《晚点 LatePost》发布的消息,最近大模型创业公司月之暗面完成了8 亿美元的B轮融资。同时,另一家大模型头部公司也在进行高达10亿美元的新融资。两笔10亿美元融资,加起来超过去年中国大模型领域的公开融资总额(约100亿元人民币)。
整个大模型赛道上的马太效应已经较为明显,市面上钱就这么多,头部玩家拿得多,其他中小型玩家拿到的融资就相当少了。
值得注意的是,大模型创业公司背后的投资名单里,密集出现了阿里、腾讯、百度、美团等互联网大厂的身影。不过,互联网大厂的投资风格,跟移动互联网时代有很大不同。
拿此前共享出行里滴滴和快的的烧钱游戏来说,背后分别是腾讯和阿里的博弈。双方多的时候一天投入4000万元,但互相都不敢收手,否则就前功尽弃。最后在资本的撮合下,双方握手言和,滴滴和快的合并。
移动互联网时代的烧钱游戏,更多的是对垒,竞争的火药味很强,而且烧钱的规模更为宏大。
而在眼下的大模型时代,互联网大厂少了些博弈、多了些和气,并且从一开始就站在同一队伍里。比如,阿里、腾讯、美团和小米都投资了大模型创业公司智谱AI 和百川智能。互联网大厂们似乎并不愿开启声势浩大的“烧钱游戏”,而是一致投向了头部选手。
这意味着,除了头部选手之外,其他中腰部的大模型创业者融资的难度在加大。要知道,在2023年初一些大模型创业公司只需要展示PPT就能获得融资,现在则需要花费更多的功夫了。
总之,从移动互联网到大模型时代,大家都在期待又一场滋滋作响的烧钱游戏,但实际上并没有发生。
那么,背后的核心原因又是什么?

成本与收益的数学题
不管哪个时代的“烧钱游戏”,对于背后的资本来说,锚定的两个本质是不变的:
成本和收益。
如果某项生意的成本可控且在承受范围内,同时收益肉眼可见且足够具有诱惑力,那么就会吸引大量资本涌入。
为何移动互联网时代,开启了多次烧钱游戏?正是因为许多生意的成本和收益都让资本足够放心。拿互联网史上最疯狂的“千团大战”来说,由于美国团购网站Groupon的成功,资本认为该模式的成本可控,且在国内复制成功的机会极大,收益极高,因此疯狂涌入。
面对如今的“百模大战”,从成本和收益两个方面来看,资本的态度是极为审慎的,这也是国内大模型赛道没有开启“烧钱游戏”的关键原因。
成本上,大模型显然是一个猛烈的“吞金兽”,需要非常庞大的资金。最近,OpenAI被曝出单月收入超20亿美元,但仍处在亏损状态,可见成本之巨大。这是因为大模型要发挥出能力,需要两个“大”:
数据大和算力大。
要想让大模型有更全面的认知和更准确的预测,庞大数据是必备的基础,它可以提供丰富的信息不断训练和优化模型。在训练阶段,大算力可以加快模型优化的速度,从而使得模型更快地学习,实现更高性能。
当然,要想马儿跑得快就要给马吃草。要实现更庞大数据和强大算力,就需要投入巨大成本。千亿级的通用大模型训练成本,往往达到千万甚至亿元,普通的创业公司往往难以承受。
并且, 即便大模型创业公司也在数据和算力上开始投入,又会带来两个新的不确定性。
一个是一旦开始投入,成本变得难以估量。即便是OpenAI这样不缺钱的头部玩家,也不确定未来还需要多少成本,更何况那些中小型的创业公司。这就极可能让竞争进入持续的军备竞赛,烧钱就会变得不可控。这就好比当年滴滴和快的竞争,最后烧钱变得疯狂且不理性。
比起成本高昂,资本更担忧的是成本不可控。
另一个不确定性是如果大模型创业公司持续布局数据和算力,也需要在硬件设备上进行高投入,整个公司会变得非常“重”。这在短期内不仅会影响收入也会影响估值,进而让投资人的回报增加更多的不确定性,这也是投资人所担忧的。
如果成本过大且不确定性因素较高,但收益是可观而且清晰可见的,那资本也会考虑加大投入。不过,大模型还处于商业化早期阶段,很多盈利模式并不清晰。
目前来看,大模型的商业化无非就是在C端和B端两头进行。C端商业化一般是通过大模型为用户提供新产品和工具实现盈利。不过,要激发C端用户的换新需求,除非有颠覆性的技术或者产品带来创新体验,否则很难吸引他们,更别提让他们付费。
短期内,大模型的C端付费用户很难有较大规模的增长。那些布局C端的大模型企业,更多的是在积攒市场关注度,赚个吆喝。
要赚钱,还得是靠ToB。
这是因为,B端企业的需求和付费意愿都比C端要强。很多B端企业本身就有处理复杂任务的需求,同时也有资金和数据,天然跟大模型适配。
不过,B端商业化虽然是条正确的道路,但也没有那么容易走。从过往产业互联网的进程来看,B端商业化从来都是块难啃的硬骨头。前期需要大量的投入,并且产出的速度较为缓慢。并且,很多B端企业的要求愈发严苛,必须看到实际的效果才愿意付费。
因此,对于资本来说,大模型的成本和收益都具有较大的不确定性,很多投资机构持观望和审慎态度,并没有催生出大规模的“烧钱游戏”。

投入与产出的平衡术
没有出现“烧钱游戏”,并不意味着国产大模型就不需要大规模投入了。
事实上,眼下国产大模型里的头部项目,每一个都离不开真金白银的投入。只是这种投入,不是“烧钱游戏”那种粗暴的、追求短期回报的,而是细水长流、追求长期主义的。
根据《人工智能大模型体验报告3.0》等报告,主流大模型中综合实力排在第一梯队的是科大讯飞的星火、百度的文心一言和商汤科技的商量。
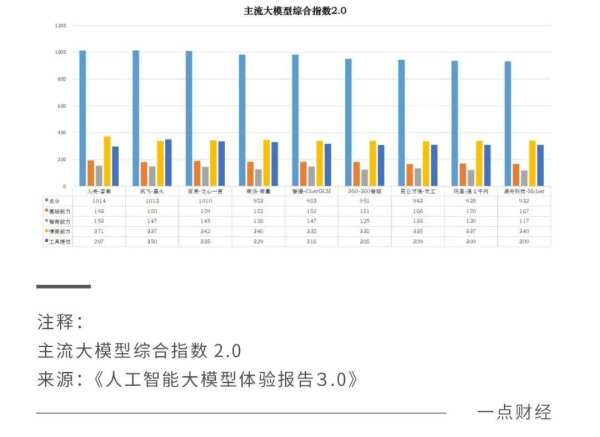
这三家企业还有一个共同的特征,那就是舍得在研发上投入。移动互联网时代,百度一度被当做掉队者。但其2011年~2020年十年研发总费用增长超过13倍,为其在大模型时代的领先打下了基础;科大讯飞2023年前三季度研发投入达到24.98亿元,同比增长7.19%;2018年至2021年上半年,商汤的研发投入甚至超过了营收。
这三家做大模型的思路,也有相似的地方,都是打造基础设施,最终吸引各方参与做生态。科大讯飞偏向智能硬件和独立软件,百度偏向支撑原生应用的开发和产业的AI赋能,商汤偏向以“大模型+”拓宽边界,让金融、汽车等行业的企业能随取随用AI能力。
三家企业旗下大模型在国内的领先,也向市场验证一个道理:大模型不是通过玩概念就能冲出重围,而是要真金白银的投入。
不过,对研发的长期的大力投入,对业绩也造成了不小的压力。科大讯飞2023年三季度的归母净利润暴跌82%,前三季度归母净利润更是公司近十年来前三季度最低的一次,就是源于对大模型的过多投入。2018年至2021年,商汤的亏损呈现上升态势,2023年上半年仍未实现盈利。
尽管百度没有出现净亏损,但是收入结构有待进一步优化。2023年第三季度百度营收达344亿元,同比增长6%。不过,广告业务收入的占比依然超过七成,而广告收入面临着搜索引擎用户活跃度下滑和抖音、微信、小红书蚕食的双重压力。
总之,在“花钱”这件事上,国内的大模型企业还是需要警惕走向无意义的烧钱,要花在刀刃上。毕竟,OpenAI 的一份报告指出,到2030年训练大模型的成本预计将从1亿美元上升到5亿美元。即使是大型企业,面对这种高昂的投入也会有压力。
并且,相对于OpenAI,科大讯飞、百度、商汤等公司在算力、数据、应用生态等方面还存在差距,未来还需要用大量资金实现追赶。当下,这些企业应该在投入与产出上做到平衡,避免资源上的过多浪费,为以后备足粮草。

2024:分化进行时
往未来看,国内发展大模型是条确定性的道路,关键在于选择。
此前,OpenAI团队就因为技术派与商业派的交锋,上演了多次“宫斗大戏”。在国内,一个同样重要的选择题是:
选择基础大模型还是垂直大模型。
这是一个现实问题。
越来越多的投资者和创业者发现,基础大模型需要的成本难以估量。那些中小型的创业公司没有能力也不愿意承担这些成本,也就难以在基础大模型领域取得突破性发展,难以跟大规模投入的巨头同台竞技。
未来在基础大模型领域,只有百度、科大讯飞、商汤等少数实力雄厚的科技巨头能够留在竞技场内。
而垂直大模型,相对来看需要的成本更小,同时能够帮助中小创业公司在细分领域寻找更多的商业化机会,获得生存机遇。比如,垂直大模型可以深入到细分产业和企业,针对特定领域或问题进行优化,包括语音识别、图像分类等等。
可以预见,“分化”将成为2024年大模型赛道的关键词。
一方面,千亿、万亿级别的基础大模型仍在持续进化,它们代表着大模型赛道上最顶尖的技术和实力,能够处理多种任务和领域的模型,往“大”的方向走。
另一方面,垂直大模型也会不断的涌现,它们专注于做小和做精,跟各行各业相结合解决特定的问题,朝着产业化的方向探索。
红杉美国就在关于大模型的报告中指出,大模型的“第一幕”是发现了基础大模型这个新的“锤子”,眼下市场正在进入“第二幕”,将端到端地解决人类问题。
从基础大模型到垂直大模型,其实也是让创业者集体回归理性。大模型风口袭来的时候,很多创业者对其有着无限向往和盲目崇拜,同时又高估了资本的参与度和自己的实力,因此一窝蜂涌向基础大模型。结果发现,既融不到钱也赚不到钱。如今在垂直大模型领域,真正到了考验创业者是否能够解决实际问题的时刻。
当然,留给垂直大模型创业者的时间并不多。
很多大模型创业者,在赚钱这件事上依然举步维艰。风投公司Theory Ventures调查数据显示,在所有AIGC公司中,95%的公司年收入平均还不到500万美元,一些估值达到数亿美元的初创公司甚至还未有收入进账。同时,科大讯飞、百度、商汤等旗下的大模型,已经向多个产业蔓延,提供差异化的模型服务。
如果垂直大模型创业者迟迟无法盈利改善现金流,同时资本持续持观望态度,那么所谓的“百模大战”到最后只会出现大量黯然退场的创业者。

结语
几百个大模型集体涌现的时候,不少投资人质疑:
国内真的需要那么多大模型吗?
当浮躁褪去回归理性,大模型创业者应该拥有更为正确的认识。既不要高估大模型的能力,尽管它能实现降本增效,解决产业问题,但还有短板没有补上,同时也不要高估自身应对资金、成本等难题的能力。
在如今不确定性因素较多的商业环境下,资本首先要求稳然后逐利,并不会大肆地广撒网、大撒币。大多数人,可能并不会成为被资本挑中的那个人。
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!
9月24日,2025云栖大会在杭州开幕,阿里巴巴集团CEO、阿里云智能集团董事长兼CEO吴泳铭发表主旨演讲,首次系统性地阐述通往ASI的三阶段演进路线,包括智能涌现、自主行动以及自我迭代等,实现从学习人、辅助人到超越人的发展脉络。基于上述的发展路线,吴泳铭对外做出判断,大模型是下一代的操作系统。“我

文/二风来源/节点财经每年高考成绩放榜后,数千万考生和家长将迎来另一场硬仗——填报志愿。今年,这一领域迎来了AI的全面介入,多家互联网大厂和教育公司纷纷推出智能志愿填报产品,为考生提供院校和专业选择建议。据艾媒咨询数据,2023年中国高考志愿填报市场付费规模约9.5亿元,近九成考生愿意借助志愿填报服

崔大宝|节点财经创始人进入2024年,大模型似乎有熄火之势:资本市场,与之关联的概念炒不动了,英伟达股价动辄暴跌重挫,引发“泡沫戳破”的担忧;消费市场,BATH们的推新活动少了,产品更新迭代的速度慢了,民众的关注度降了……热闹的大概只剩下两场酣仗:自5月15日字节跳动宣布“以厘计费”,打响国内大模型

年初大模型行业上演“长文本”大战时,我们就萌生过做一个“读书助理”的想法。测试了市面上主流的大模型后,发现普遍存在两个不足:一种是可以处理的文本长度不够,即使有些大模型将文本长度提升到了20万字,像《红楼梦》这样近百万字的名著,还是需要多次才能“读”完。另一种是语言理解和生成能力不足,经常出现“幻觉

2026年,企业使用大模型API的方式已经明显变化。早期团队更关心“能不能调到模型”“价格是不是便宜”“模型列表是不是够多”,但当大模型能力进入客服系统、代码助手、知识库问答、内容生产、数据分析、智能体任务和内部自动化流程后,API调用层本身就变成了生产基础设施。此时,AI聚合平台、AI中转站、AP

摘要续航、性能和AI,这三件原本互相打架的事,正在一台轻薄本里慢慢和解。我上一次正经用一台Windows笔记本,已经是上学期间,很多年前的事了。记忆还停留在上学那会儿,为了打游戏,我背着一台又厚又沉的「游戏本」在宿舍和教室之间来回,包带勒在肩膀上,键盘下方烫手,电池撑不过两节课,离了插座基本等于半残
痛点引入与概述(Introduction)只要你是一名国内开发者,一定经历过这样的抓狂瞬间:·在各种代理间反复横跳,只为了让claude命令能执行超过10秒不报ConnectionTimedOut;·好不容易注册的Claude账号,下一次claudecommit时直接提示Youraccounthas
随着大型语言模型在研发、产品与业务中渗透得越来越深,技术团队面对的现实不再是“要不要用”,而是“怎么高效、稳定、合规地调用几十上百种模型”。直接逐一申请各家官方的APIKey,管理成本高、切换成本更高,而模型供应不稳定、账单零散又缺乏企业级管控的痛点,让API聚合平台和API中转站成为技术栈中不可或

二手手机回收看似简单,实际涉及价格评估、设备检测、物流交接、隐私安全、付款结算、争议处理等多个环节。对用户来说,最担心的往往不是“旧手机能不能卖”,而是“价格是否合理”“寄出去是否安全”“检测后会不会变价”“手机隐私会不会泄露”“如果不满意能不能退回”。合肥曦诺传媒有限公司作为一家面向全国客户提供二
当你的团队开始把ClaudeCode和Codex当作日常编程搭档时,一个被反复低估的难题会浮出水面:这些工具的模型配置不像玩具Demo那样一键切换,真正落到生产环境,你会撞上API兼容性、Token消耗追踪、多账号权限管理这些实打实的工程问题。不少团队卡在“能调通”到“能管好”之间的鸿沟里——接口地
文/郭静来源/节点财经据TheInformation报道,DeepSeek已完成首轮外部融资,募资总额超500亿元人民币(约74亿美元),估值达到500亿美元。如果消息属实,这将是国产大模型乃至整个中国AI行业迄今为止最大的一笔单轮融资。互联网、制造业、老牌资本、国家队,一样不缺——梁文锋亲自坐庄,

“PC正在被重新定义,这次重塑的意义堪比当年手机向智能手机的变革。”6月1日,英伟达CEO黄仁勋在COMPUTEX2026(台北国际电脑展)上进行了一场近2小时的主题演讲。在演讲中,他从口袋里掏出了一块面向个人AI电脑的超级芯片—RTXSpark,宣告智能体AI(AgenticAI)时代已全面到来。
团队启动了一项关键的代码库现代化项目,目标是将遗留的Python服务迁移至更健壮的架构,并利用前沿模型进行全量代码审计与重构。评估了多个选项后,我们决定采用ClaudeCode,看中的是ClaudeOpus4.8在SWE-bench上展现出的顶尖推理能力以及其超长上下文处理窗口,理论上非常适合处理我
每到节假日出行,买火车票就成了不少人头疼的事。高铁票用什么平台买比较靠谱?哪个平台抢票成功率更高?支付方便吗?出票快不快?怎么买才划算?这些问题几乎每个坐火车的人都遇到过。从实际使用体验来看,市面上几个主流平台各有特点,但从功能完整度和省钱力度上,同程旅行近期的表现值得关注。一、抢票成功率,取决于平













