从Excel、报表系统到传统BI,企业数据分析工具进化的同时,背后需要支持的数据承载量也在以更快的速度一路攀升。
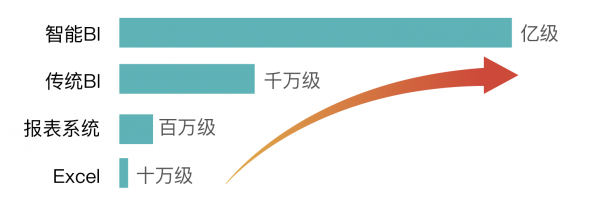
(各数据分析工具适合承载的数据量)
以一家连锁零售企业为例,如果门店有2000家,在售SKU有5000个,一天单店单品库存数据量就达到了1000万,一周就可能破亿。
为了能让性能跟上企业数据发展的速度,确保用户在亿级、十亿级数据集的基础上还能做丝滑的拖拽式数据分析和动态查询,同时又不会给IT人员带来额外的数据管理与运维压力。观远数据在2019开始研究基于海量数据计算查询的加速组件,并于2020年3月正式推出“极速分析引擎”黑科技功能,真正做到十亿级数据秒级响应。

“极速分析引擎”是嵌入在观远一站式智能数据分析平台中的一套计算查询加速组件,在集群模式下最快支持十亿级以上数据秒级响应速度。适用于零售行业大数据量、大宽表、高并发的数据分析情况,比如海量库存数据聚合分析与查询、订单分析、商品分析等场景。可以满足业务人员持续的探索式自助分析、即席查询、动态分析的需求,保持连贯的分析思路,打造沉浸式分析体验,深挖数据价值,高效洞悉业务。
“极速分析引擎”到底有多快?我们在实验室环境下做了一个性能测试。测试的机器为16核128G内存的单节点,未做加速组件的独立部署(实际上加速组件可单独部署,加速效果更明显)。
Demo1:极速查询演示视频演示-https://v.qq.com/x/page/u09471ficps.html
以上案例中,我们模拟了某零售客户基于订单商品明细数据的任意时间区段销量、销售额、成本的聚合分析。
可以看到,左右两张表都是基于同一张1亿行的订单明细表进行聚合分析。区别在于左边的表是使用的是Guan-Index数据集,是利用Spark计算引擎来进行计算的。而右边的表则是使用“高性能查询表”,利用“极速分析引擎”来做加速查询的。不难发现,在切换日期区间时,右侧表格基本上能够在2~3秒内返回计算结果,而左侧表格则需要10秒才能返回,整体的性能提升达到3~5倍,真正做到亿级数据秒级响应。
Demo2:一亿行数据自由拖拽式分析-https://v.qq.com/x/page/a094711g02i.html
还是基于以上数据,我们再做一下自由拖拽式的数据分析进行测试。从Demo中可以看到,基于1亿行订单明细数据的自由拖拽分析,也可以做到秒级响应,丝滑体验。
如此强大的功能要怎么使用?
当用户导入千万级以上Guan-Index数据集,或者通过Smart ETL生成同等体量的数据集后,想要使用“极速分析引擎”来进行查询加速时,我们可以大致分三步进行操作。
1、配置数据集
我们可以进入到数据集详情页“高级选项”栏,将数据集配置为“高性能查询表”。
2、设置分区字段
用户需要设置分区字段——分区是为了数据在存储时能合理地分片,以减少数据查询时的数据扫描。一般建议使用日期字段来做分区,分区方式建议设置为“月”或者“日”。使用日期字段做分区,可以有效地控制分区数量,不至于把分区做得过粗或者过细。如果没有日期字段,也可以谨慎选择其他字段进行分析,这时需要控制好分区字段的枚举数量,一定不要选择类似订单ID之类的流水号,或者数值类字段作为分区字段。
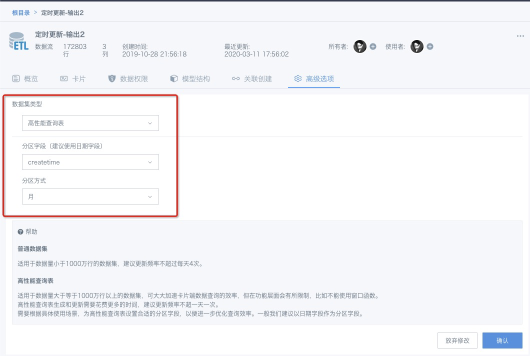
3、确认执行
配置完分区字段后,点击“确认”即可以开始模式切换。数据集数据量大的时候,数据导入需要花费一定的时间,请耐心等候。内部测试,3亿行*26列的数据集导入花费12min左右。数据集更新也会触发数据重新导入,因此一般建议高性能查询表更新频率不超过一天一次。
以下就是一个配置了“高性能查询表”的ETL输出数据集,我们看到表面看起来它似乎与一般的ETL输出数据集并无二异。但我们在使用它创建卡片时,却是利用“极速查询引擎”来查询数据,能够提供飞一般的体验。
“极速分析引擎”适用于哪些场景?
目前,“高性能查询表”适用于数据量大于等于1000万行以上的数据集,可大大加速卡片端数据查询的效率。并且特别适合海量数据下的OLAP查询,适合在大宽表上做任意维度的数据聚合、切片(筛选),也可以做明细数据的查询。这些查询相比直接使用Spark作为计算引擎,一般都能提供3~5倍的性能提升,如果硬件资源宽裕,将加速组件独立部署,将能获得更为优越的极速体验。
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!
第六届进博会期间,全球数据和分析驱动的决策赋能机构邓白氏(Dun&Bradstreet)以“共创可持续发展的未来”为主题亮相服务贸易展区。作为连续四年参加进博会的“老朋友”,邓白氏于此次参展期间,在中国首发“供应链ESG解决方案”,并展示一系列数字化解决方案,赋能中国企业构建可持续发展的韧性供应链。

近日,神策数据发布了全新的神策分析2.5版本,该版本以经营分析为主题,支持分析模型与外部数据的融合性接入,构建全域数据融合模型,并提供统一、便捷的指标及可视化能力,实现从用户到经营的全链路、全场景分析。经营分析可以帮助企业更深入了解用户的需求,构建从用户到经营的业务指标体系,尤其针对需要加强数据融合

2023年6月1日至4日,第三届全国生物相分离和相变学术研讨会暨中国生物物理学会生物大分子相分离与相变分会年会在上海成功举办,荣联科技集团携冷冻电镜数据分析整体解决方案亮相活动,云生数据副总经理田凤进行了精彩的报告分享。本次盛会由中国生物物理学会生物大分子相分离与相变分会主办,中国科学院上海有机化学

如今,诸多企业开始进入数据应用阶段,开始追求数据对业务的实质性提升。然而,一些企业虽然认识到了数据的价值,却由于缺乏一套高效好用的数据分析工具,导致数据应用效果并不理想。在一些企业中,尤其是中小企业,由于缺乏预算,仍然在使用Excel等传统工具进行数据分析和可视化展现,需要手动整合和处理数据,耗时耗

数据收集的操作行为受到越来越多的关注,也变得越来越复杂。网络抓取以及自动获取过程总体来说极大地改变了数据收集的性质,旧的挑战得到解决,而新的问题也随之浮现出来。
把脉中国数据智能化

2023年,几乎可以被定义为中国互联网公司的“大模型元年”。ChatGPT的全球爆红,彻底点燃国内的大模型赛道,曾经的“创业英雄”、如今的商业领袖们亲自下场,接连发布生成式人工智能产品与大模型布局。大模型火了,沉寂许久的互联网行业又有了新的“战事”。同时,大模型的快速发展也改变了云市场的现状,企业对

近日,数字化市场研究咨询机构爱分析发布了《2022爱分析·数据智能厂商全景报告》,爱分析从技术研发能力、服务客户数量、收入规模等维度对厂商进行了全面专业的评估

2022年11月18日,首个国家级大数据产业创新赛事——2022第一届中国大数据大赛圆满落幕。工业和信息化部信息技术发展司数字经济推进处处长张建伦,中国电子技术标准化研究院副院长孙文龙出席颁奖典礼并致辞

2022年11月17日,在厦门市工业和信息化局的指导下,以“数据确权”为主题的2022数据资产(厦门)论坛在厦门成功举办。本次论坛以“数据确权”为主题,由厦门市互联网域名应用服务产业协会和构信网(公信.中国)联合主办
近日,国内知名数字化市场研究咨询机构爱分析正式发布《2022爱分析·信创厂商全景报告》(以下简称“报告”)。报告综合考虑企业关注度、行业落地进展等因素,遴选出在信创市场中具备成熟解决方案和落地能力的厂商。

10月31日下午,由数博会执委会主办、数据观(北京)传媒科技有限公司承办、贵阳大数据交易所协办的第四期数博思享会“实践先行观公共数据价值与应用”活动成功举办。
近日,由中国国际数字经济博览会组委会主办,中国电子技术标准化研究院、河北省工业和信息化厅承办的“第一届中国大数据大赛”(简称大数据大赛)正式启动。

广州光点信息科技有限公司自主研发的数据中台产品GI大数据中台V2.0产品是国内率先推出符合新创标准的中台产品,基于“大数据+AI”等技术全新打造,集数据采集、融合、治理、服务、管理为一体的旗舰平台。

广州光点信息科技有限公司自主研发的数据中台产品GI大数据中台V2.0产品是国内率先推出符合新创标准的中台产品,基于“大数据+AI”等技术全新打造,集数据采集、融合、治理、服务、管理为一体的旗舰平台













